Tetris Attack with RL
Intro
Wow, I really need to plan my projects better because this one took me way longer than it should have. I followed a lot of Nicolas Renaut's tutorials on youtube to get me started.
The general idea behind a reinforcement learning model is to give your computer a "reward" every time it makes a "good" move and optionally give it a negative reward when it makes a bad move.
From there your computer is going to take mostly random actions to start but over a few hundred thousand or million timesteps it will start to realize what good action it needs to take to get better reward.
A good example would be a super mario level. Give the computer a reward for every time it moves right and over the course of a few million timesteps and in game deaths, it will maximize its move right reward until it reaches the end of the level.
I decided to use this on Tetris Attack, originally I planned for Pokemon Puzzle League, but they are the same game and Tetris Attack is supported in OpenAi's gym (basically a python library that makes reinforcement learning easier).
Tetris Attack
Tetris Attack is a horrible name for the game, bacause it has nothing to do with Tetris. The goal of Tetris Attack is to match up similar colored tiles to get points. Think candy crush kinda.
You get more points if you match more tiles and you can chain matches together if you make them in quick
succession. Here's someone playing the versus mode
I trained my model in single player endless mode, because I think AI should be pacifict :).
Parameters and Tensorboard
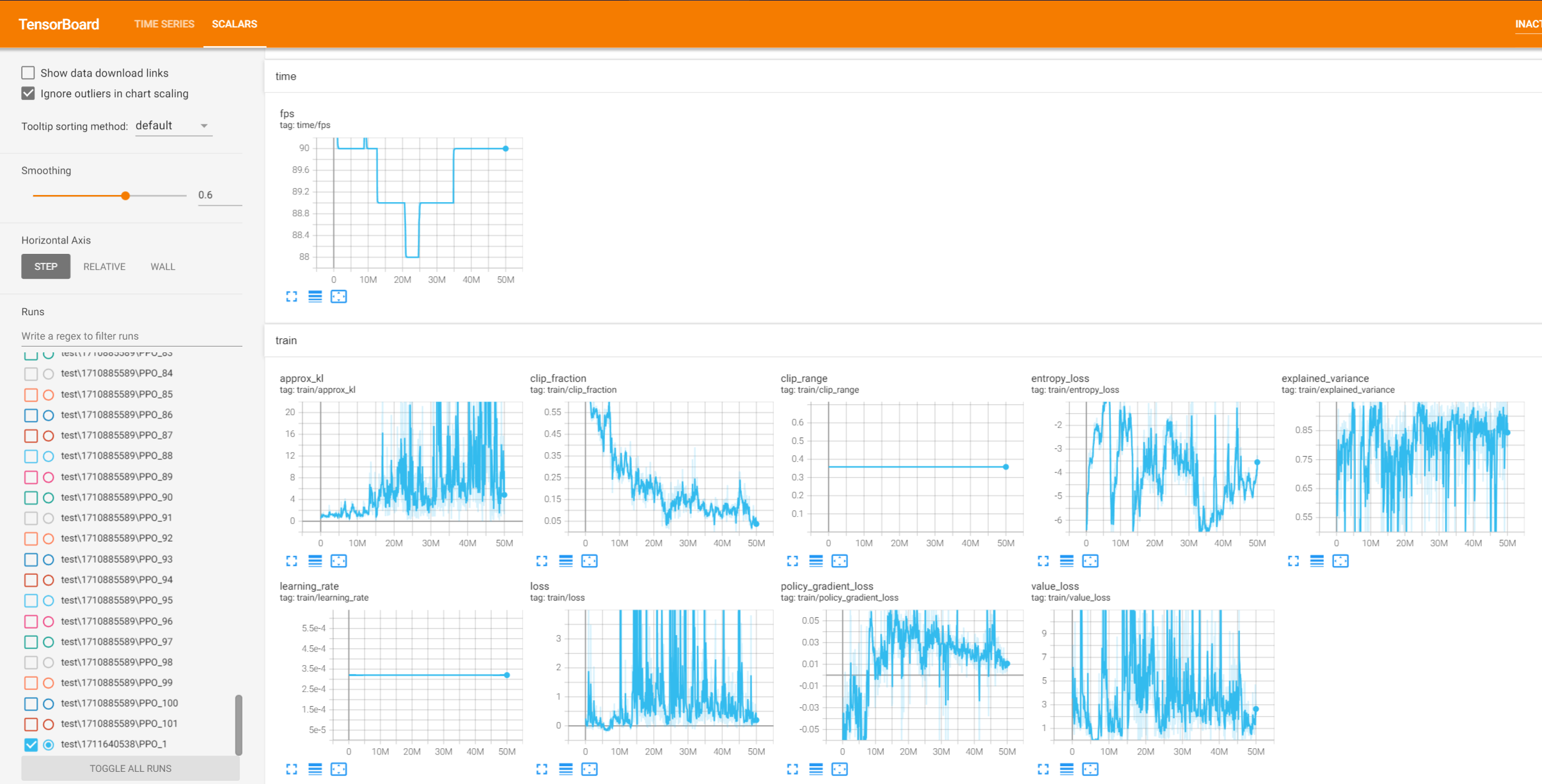
Tensorboard is another python library that tracks your models progress and parameters as it trains. I'm not what I would do without it as my model trained and failed a ton of times, and that was what I used to debug.
Parameters are what make your model its own basically. Learning rate and entropy coefficient and n_steps are all variables that determine what your model will do as it learns. I won't go over each one but these are whats tracked in tensorboard.
Unfortunatley I'm somewhat of an idiot on my final model I grayscaled the game so it would process faster, and failed to wrap the new environment in a monitor so I wasn't able to track the reward in tensorboard.
I ended up using kl and explained variance to determine what was happening. kl is how different your model is every generation, the higher the value the more change is happening each gen.
Explained variance is how well is your model at predicting the reward for a given action, basically does it know what's happening and why. What you want to see from these is kl lower and explained variance rise over time.
Here's an image of the tensorboard parameters of my final model
Hyperperameterization
Not entirely confident thats a word, but for this I used optuna, another python library. Hyperperameterization is the idea of training a ton of models for a little bit all with different paramters and then taking the best one.
For this I trained each model 100k timesteps and I trained 100 models. Be warned that this step in the process can take forever, 100k timesteps was really not enough to determine the best parameters.
All those PPO models you see on the right of the image in tensorboard are all the different models I trained for this step. (Takes up a ton of space too).
Optuna is a super cool library though, it is able to tell as it trains the models which parameters worked better and weight those higher as it explores the parameters in future models.
Training
Once you actually get some good parameters, you can start training your model. This time I used the stable baselines library. This process is really only a couple lines of code to setup the env and then determine the length of training
I decided to train the model for 50million timesteps because I trained it in the past for much smaller increments and nothing was working. This was really throwing something at the wall to better determine what was happening, luckily for me it just worked.
That means of course that before this I was never training my model for long enough, and based off my parameters I still had a lot of room before I reached convergence on this model too. Kl is getting higher, which means my model is probably still improving!
Gym and Reward
Gym is not only a place where you ball, its ANOTHER library I used for this project. OpenAI (chatGPT woo!) made this for reinforcement learning and it creates the game environment for a lot of SNES and earlier games
The environment also includes the all important reward function and it is a pain in the ass to find anything online about it because this library is legacy now. Im so lucky too because it turns out their reward function for tetris attack sucks!
The game tetris attack has a score based off the current level, how many matches you've made, and also how often you speed up the of the wall to match things on. That last bit is important so I'll try to explain it clearer.
In the game the wall of tiles will slowly creep up to the top of the screen, if it reaches the top, you lose. You can also choose to speed up the rate of the wall rising, to get more tiles and make more matches if the normal rise is too slow for you.
The problem is you get a point for every timestep you do this, and gym had the default reward function map directly to the score in game. Which means that every time you click speed up, you get a reward.
It took way to long to realize that the model would realize speed good and speed to its own death over and over to get an average score of 6 (you get 30 for a basic match). This convergence isn't ideal at all so I went in and changed it.
I tried a couple things but I settled on just removing that from the reward function, gym gives you a nice little tool to find out where these values are stored in your memory so mapping your own reward function isn't too bad
I mapped a flag to if the speed button was on, to remove a point from the reward, this would perfectly match the rate of the increase in score of the game so the reward function essentially just ignored any speed button.

This is the new reward function, -1 for gofast is the marker I added as well as the lua script. The lua script is just restarting the env if you can't make a match quick enough. The idea was to make the model avoid twiddling its thumbs
Final Model
Wow, look at that little guy go.
Closing Thoughts
I stated before but I still think the model isn't even close to convergence, which I think is pretty cool considering how long I trained it for (50 million timesteps took about a week in real time of training)
That makes it hard to speculate on the performance itself though too, I think it could be making these matches a lot faster though, to fix that I think I'd need to incorporate the time value in the reward function
I also think that in terms of preprocessing, I really should have expiremented more. Grayscaling definilty helped but there are other ways I can make the game easier for the model to process.
Reinforcement learning itself also has no real world function as of right now, it is cool to see this function on a game, but for it to work on a real environment the amount of resources it would take is insane to thing about.
I will post the code on my github eventually once I update the link, feel free to copy or use it in any way you want. (insert link here eventually please future Nick)