ASL Predictor with YOLO
Intro
Welcome back to another project! This was finished in March of 2025, going back I realized dating my projects will be really nice to mark the progress I've made. Lets get into this project and what I did. This project is a real time feed of my webcam, with a display on screen of what sign language letter I am holding up. I'll refer to the sign langauge as ASL (American Sign Language) and the model algorithm as YOLO. I'll break down piece by piece the process and how the model actually works
Getting Started
I had never done real time image prediction before, and I had no idea how to start. I have done quite a few kaggle challenges up to this point though, as a way to teach myself pytorch as well as getting a better grasp on deep learning. So let me explain that really fast, so that what I'm gonna talk about in a bit makes more sense. Kaggle is a website for data scienctists that has collections of datasets and challenges and tutorials all centered around data organiziation/cleanup/predictings. Deep learning is another name for neural networks. I won't go into the math behind it (watch statquest!) but the general idea is that you have some initial data that has a clear input AND a clear output. IE medical dataset might be like a list of patients and their medical info, and the output would be whether they are sick or not. It's important for the test data to have that defined output, so that your model can predict upon future datasets when there's input data and no output data. In our example it would be when a new patient wants to know if they are sick. We feed the model we generated on all those past patients info this new patients medical info, and then the model predicts if he's sick or not based off all that past data (and math) the model is built off. This is called supervised learning, a basis of machine learning. I mentioned it briefly before too, but pytorch is a deep learning library made by meta to make it MUCH easier to apply these concepts.
Trial 1
My first attempt at this ASL bot was orignally thought up when I saw a kaggle dataset of someone spelling out the ASL alphabet. The dataset is enourmous with around 80k images of just hand letters. https://www.kaggle.com/datasets/grassknoted/asl-alphabet .
Props to the guy who made this its an excellent resource that must've taken forever. To start with my model, I created just a normal prediction model, it takes a still image (from that dataset) and predicts on that image one of 26 classes for each letter in the alphabet
That was pretty simple to make, and from there I though, why don't I just apply that model prediction model to like a 30 fps camera feed in real time? (Running the model 30 times a second) Surely that will work.
Suprise suprise that my first try was a complete failure. It turns out that trying to run even a simple model like this 30 times a second is a little unrealistic but more importantly, my webcam feed is 1920x1080, and these images are 480x480.
This is important because in predictive modeling, your input data from your training data to your testing data has to be EXACTLY the same. If I train a model to predict on 480x480 small images, it won't know what 1920x1080 images look like.

Trial 1.5
Alright I was a little stubborn on the whole application to 30fps feeed thing. My next idea was to stay with the first idea, but instead of training a model on 480 images, train it on 1920x1080 images. That way I can just plug it into my webcam.
I REALLY didn't want to create my own dataset, because that is a ton of work, so instead I grabbed each image and wrote a tiny script that expanded each 480x480 image from the kaggle dataset into 1920x1080 images, with the remaining space just filled with blackspace.
I then trained a new model on this dataset and plugged it into an image pulled every second on my camera feed (so I guess running on 1 fps) and this worked! It would display in terminal, which letter it thought I was holding up with about 60% accuracy.
Not bad at all for real time predictions. Still I wasn't too happy with this, it wasn't what I envisioned. For one, if I held up two hands with two letters, it can only predict on one. Plus the model can't predict where the letter is in the feed, just that it exists.
YOLO
I don't just mean YOLO like you only live once, I mean the algorithm. I went online, because I'm well aware this project has been done before, and found that most people use real time algorithms for webcam feeds. The most popular being YOLO for live feeds.
I won't get into the math (again) on how YOLO works, but the general idea behind these algorithms is the same as always. Have input data and output data to train on. In this case YOLO has bounding boxes.
Bounding boxese are these little boxes on the image that tell you where it is, so when you train your model, you link to the image set, as well as a text file that has the location of the object you are trying to detect.
This is great! This means that I can literally just use the old dataset, and create a text file with location of where I started padding the image with blackspace so that YOLO can detect where the real kaggle image is.
So I did exactly that, I padded all the images the same, leaving the original in the top right 480x480 pixels of the whole 1920x1080 image, the rest being blackspace. Then I made a text file listing 480x480 for the bounding box.
This did not work.
It ended up not predicting anything in my live feed, and I was hoping it was just because all the objects were in the same location in the training data. So I created a random padding method that started putting the original kaggle image somewhere randomly within the larger image.
That would end up padding the rest of the 1920x1080 image in around that. Then I stored those random variables and added those into my YOLO text file.
Still broken.
So yea the model was pretty much unusable. It never really saw my hands as anything even after the random padding technique. But still, I would NOT relent. I am not going to sit through and monotonously create and label my own ENTIRE dataset, no way, never. I'll think up some workaround.

Buildling a Custom Dataset
So the first step in building a custom YOLO dataset is finding a software that will help make it much easier for you. I eventually stumbled accross a useful library that would let me cycle through a dataset I upload and put in a bounding box on it.
After I put on the bounding box, it would create the text file of the pixel location for me. Now as for getting images, I took a 30 second video of me 26 times, each time holding up a different asl letter.
After I had the videos I went online and found a tool that let me splice them into still images (10 images a second), I trashed the images that had no clear letter or if my hand was moving or if it was blurry so the dataset was clean-ish.
Then I got to work labeling them all with the bounding boxes. All in all I was left with about 3.5k images to label, waaaaaay less then the guy with 80k, but hopefully enough for this project.
The labeling process took me around 3 days, putting on a podcast or video in the background while I did monotonous work made it go by quicker. I used the cvat tool at https://app.cvat.ai.
After the dataset was trained, it was as simple as grabbing ultralytics (python library) yolo model off their website, tuning it to my new dataset, and displaying that yolo models results on my live webcam feed.
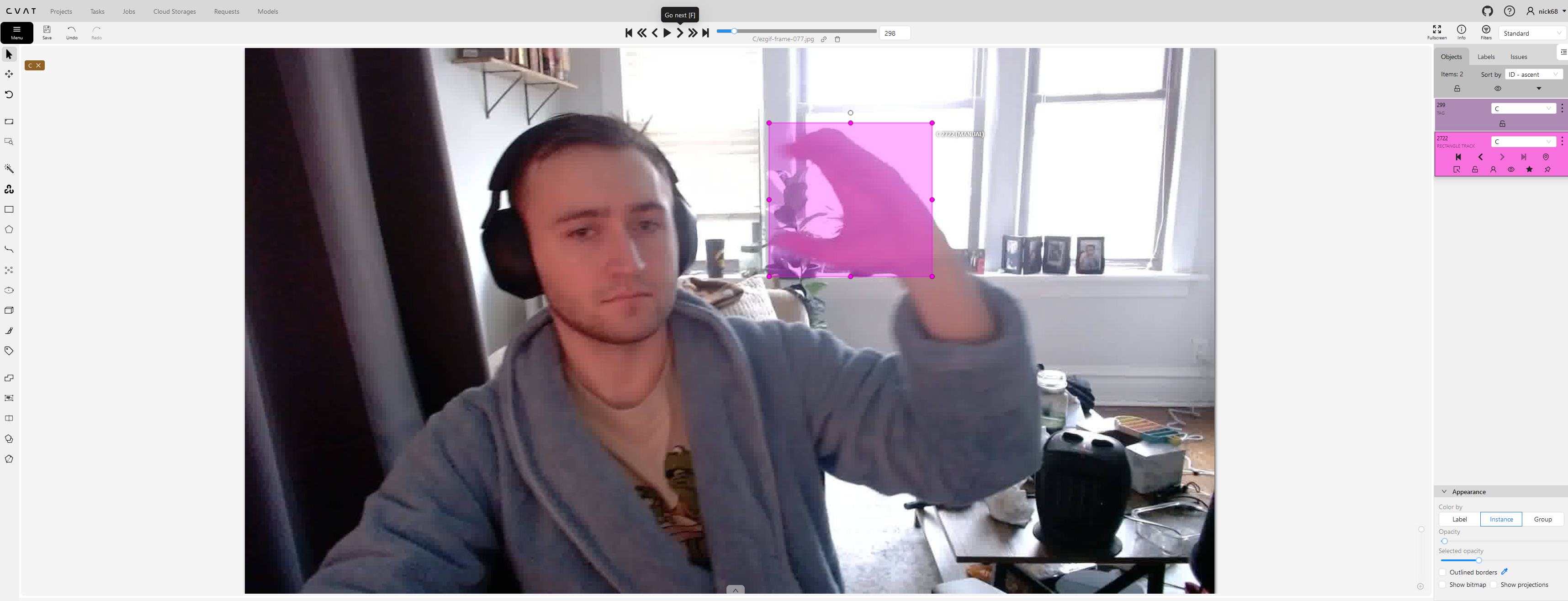
Don't judge the robe, please, it is so comfy.
Final Model
I promise I'm way happier than this video appears. Ignore the background girlfriend
Closing Thoughts
This was a super fun way to dip my toes a little in computer vision, and getting a deeper understanding on the models we have around that. My model is no where near perfect though, and it's pretty obvious why.
My dataset just needs to be so much bigger, and it really goes to show why we value data so much in the modern day. If you can track/record/log everything it gives you such an advantage to train these models.
I think computer vision has a lot of catching up to do when it comes to ML. NLP is all the rage as of me writing this, but I get the feeling that in a few years, this project will be showing its age as new vision models gets better.
It's all so exciting, and so incredibly fast moving. Can't wait to start the next project.
I will post the code on my github eventually once I update the link, feel free to copy or use it in any way you want. (insert link here eventually please future Nick)